
https://www.jesse-anderson.com/2021/09/keeping-things-stupidly-simple-with-pulsar-and-kafka/
During my interviews for another case study in Data Teams, I was introduced to a concept I teach but hadn’t heard so brilliantly stated. The case study was with Justin Coffey and François Jehl, who were both at Criteo. Justin introduced this concept of keeping things “stupidly simple”:
To keep things aggressively simple, “we looked at the primary use case and said, how can we implement that with the least bells and whistles possible in a way that’s the most repeatable and most immediately understandable to the next person who’s going to come on?'” That led them to make extensive use of HDFS. They identified anti-patterns and didn’t let users run “crazy jobs.” They focused on standardizing how data landed and was queried so it could be usable by others. They removed one-offs to make sure the primary uses cases were handled effectively.
Part of being stupidly simple included deeply understanding the technologies they were using. They chose a technology and read the papers that the creator wrote about it. “We’re going to take that, and we’re going to take this tool, and we’re going to deploy it to do that specifically, and not do anything else with it,” Justin said.
I’ve said streaming systems at scale are 15x more complex than small data. When you’re choosing a streaming system, a wrong choice for the use case can cause a massive increase in workarounds and complexity. Streaming systems are complicated enough already, and adding more complexity through workarounds just exacerbates the problem. I can’t stress this enough that inexperienced people will gravitate to more complicated architectures when a simple architecture is available. When you add or remove boxes (technologies), each one has to earn its way into the diagram or architecture because there is overhead to adding new technologies operationally, architecturally, and developmentally.
There are blog posts from Slack and Uber on their streaming systems that I want to go through. We’ll look at the workarounds they have to do, why they had to make them, and what you could do to avoid them.
Note: This isn’t a teardown or critique of these company’s projects. There are many reasons these teams chose to go these routes, and I’m more trying to point out how they could have stayed stupidly simple with Pulsar and avoided the workarounds necessary for Kafka.
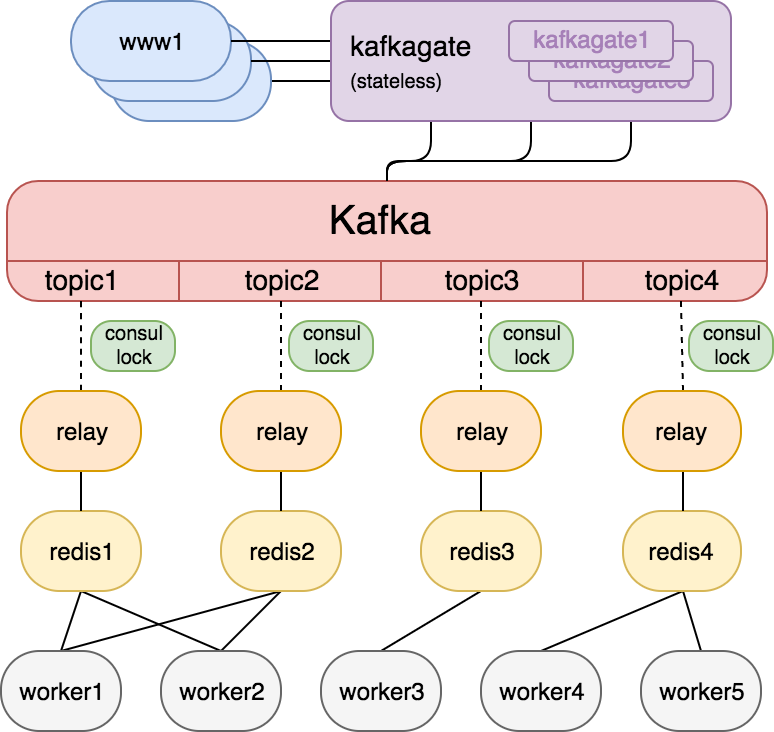
Slack’s second iteration using Kafka and Redis task queue

Slack was facing an issue with running their tasks at scale. They started by using a Redis task queue. For their second iteration, they used Kafka to put the jobs into a specific Redis task queue.
For this design, we face the predicament that Kafka is a poor choice for running tasks. I’ve written an entire post going through the reasons why. As a direct result, the team had to continue to use the Redis task queue, and Kafka is functioning more as a buffer between the website and the process executing the actual tasks. It created more workarounds and lost the simplicity of design.
This setup increased complexity at the operational, development, and architectural levels. The ops team must maintain the Kafka cluster and make sure all messages make it correctly from the website to Kafka, then Kafka to Kafka, then Redis to the final destination. This architecture is a circuitous route, to be sure. On the architecture and development side, we no longer have a single path for the data. The developers and architects must know the extra steps to copy data before the tasks can be executed.
The architecture diagram for the Slack use case with Pulsar

The design using Pulsar would be straightforward and stupidly simple. The website would queue a task into Pulsar, and task processes would consume directly from Pulsar. There would be no extra copies or circuitous routes, and we altogether remove the need for Redis and “kafkagate”.
Uber makes heavy use of Kafka but has both streaming and messaging use cases. They tried to use Kafka directly for all use cases. However, Kafka lacks support for task queues (messaging) use cases (the reason why). The team created a consumer proxy to work around this limitation of Kafka’s lack of messaging support.
It’s worth reading through Uber’s post because they outline Kafka’s messaging issues and potential data loss and latency issues.
{kind=link}
{kind=link}